
センサーデータを分析するデータ基盤候補として、Data Firehose + S3 Tables + Athenaを試してみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
はじめに
この記事はクラスメソッド発 製造業 Advent Calendar 2024の6日目の記事です。
製造現場では、様々なセンサーから大量のデータが生成されます。これらのデータは、装置の稼働状況の監視、製品品質の向上、故障予測など、様々な用途に活用できます。しかし、これらのデータを効率的に収集・分析するためには、適切なデータ基盤が必要となります。今回は、そういったセンサーデータを分析するためのデータ基盤の候補として、Data Firehose + S3 Tables + Athenaの構成を試してみます。
S3 Tablesとは
S3 Tablesは、re:Invent 2024で発表された新しいストレージソリューションで、次のような特徴を持ちます。
- 分析に特化したストレージ設計: 高いトランザクション性能とクエリスループット
- 汎用のS3バケットに比べて3倍のクエリパフォーマンスと10倍のトランザクション性能があるようです(公式ページ 記載情報より)
- Apache Iceberg: テーブルフォーマットとしてIcebergが使われるため、スキーマ進化やパーティション進化をサポートします
- 自動テーブル最適化: データのコンパクションやスナップショット管理を自動で実施
- (プレビュー)AWS分析サービスとの統合: Athena、Redshift、QuickSightなどのサービスとシームレスに連携
2024/12/6時点ではバージニア北部、オハイオ、オレゴンの3つのリージョンで利用できます。
S3 Tablesメンテナンス機能について
S3 Tablesにはテーブルバケットとテーブルに対するメンテナンス機能があります。これらの機能はデフォルトで有効化されています。
- テーブル:
- コンパクション: 一定サイズ(デフォルト512MB)のファイルになるように、複数の小さなファイルを1つのファイルにまとめます。クエリパフォーマンス改善の効果があります。
- スナップショットの管理: 設定した期間に応じてスナップショットの無効化を行います
- テーブルバケット: 無効化されたスナップショットに紐づいていたデータを自動的に削除します
しきい値を変更したり、メンテナンス機能を個別で無効化することも可能です。
やってみる
主要ツールのバージョン
- aws-cli: 2.22.12
- spark-shell: 3.5.3
AWSプロファイルとリージョンを環境変数に設定
これからAWS CLIやSparkシェルを介してAWSリソースを操作するため、事前に利用するAWSプロファイルとリージョンを環境変数に設定しておきます。リソース操作はAWS CLIだったり、マネジメントコンソールだったり操作によって楽な方で行います。
export AWS_PROFILE={AWSプロファイル名}
export AWS_REGION=us-east-1
S3 Tablesバケットを作成
S3 Tablesバケットをマネジメントコンソールから作成します
その際に分析サービスとの統合を有効化します。
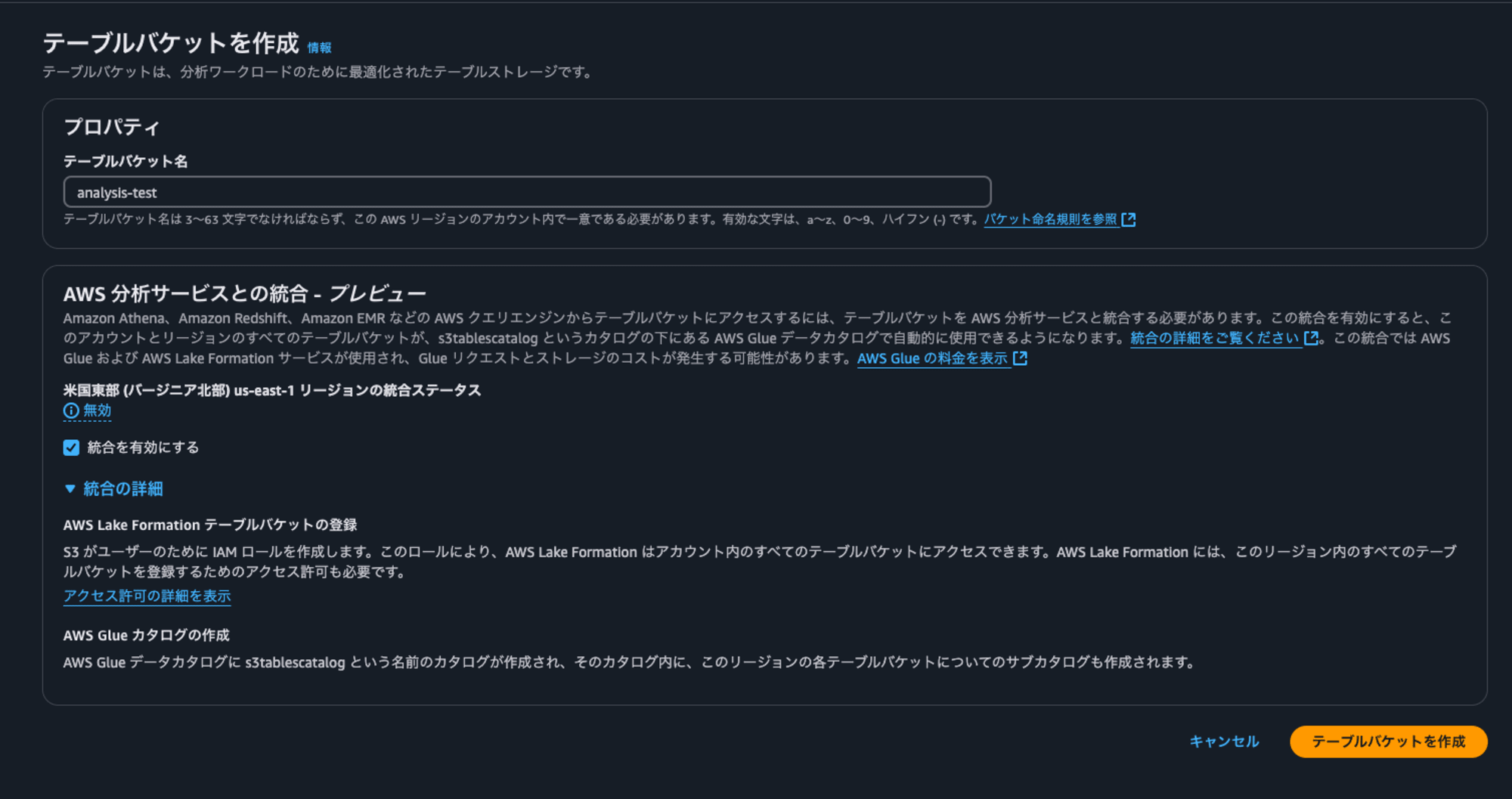
分析サービスとの統合によって、Lake FormationがS3 Tablesにアクセスできるようにするサービスロールと、s3tablescatalogという名前のデータカタログ が作成されます。これらのリソースを削除することで統合を無効化することも可能です。
S3 Tables バケットにnamespaceとtableを作成
SparkシェルからIcebergのnamespaceとtableを作成します。
※ ドキュメントを読むと、AWS CLIからでもできるようなんですが、テーブルのスキーマ指定などはできなさそうだったので、Sparkシェルから実施することにしました。
まずは、ローカルでSparkシェルを立ち上げます。その際にAWSプロファイル名とS3 TablesバケットのARNを{}で指定してある箇所に入力します。
※ ドキュメントでは、iceberg-spark-runtimeとs3-tables-catalog-for-iceberg-runtimeのみをパッケージとして指定してますが、それだけだとクエリ実行時にエラーがでたのでいくつか追加しています。
spark-shell \
--packages org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.6.1,software.amazon.s3tables:s3-tables-catalog-for-iceberg-runtime:0.1.3,software.amazon.awssdk:s3tables:2.29.26,software.amazon.awssdk:s3:2.29.26,software.amazon.awssdk:sts:2.29.26,software.amazon.awssdk:kms:2.29.26,software.amazon.awssdk:dynamodb:2.29.26,software.amazon.awssdk:kms:2.29.26,software.amazon.awssdk:glue:2.29.26 \
--conf spark.sql.catalog.s3tablesbucket=org.apache.iceberg.spark.SparkCatalog \
--conf spark.sql.catalog.s3tablesbucket.catalog-impl=software.amazon.s3tables.iceberg.S3TablesCatalog \
--conf spark.sql.catalog.s3tablesbucket.warehouse={S3 TablesバケットのARN} \
--conf spark.sql.extensions=org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions
Sparkシェルが立ち上がったら、namespaceを作成します。
spark.sql("create namespace if not exists s3tablesbucket.sample")
次にtableを作成します。
センサーの計測値をいれることを想定したテーブルを作成します。
spark.sql("create table if not exists s3tablesbucket.sample.sensor_readings ( sensor_id string, temperature float, humidity float, timestamp timestamp) using iceberg ")
selectしてテーブルを確認してみます。
spark.sql("select * from s3tablesbucket.sample.sensor_readings limit 5").show()
作ったばかりなので何もはいってないことがわかります。
+---------+-----------+--------+---------+
|sensor_id|temperature|humidity|timestamp|
+---------+-----------+--------+---------+
+---------+-----------+--------+---------+
Firehoseストリーム作成の準備
データを受け取り、S3 Tablesに作成したIceberg形式のtableにデータを流すFirehoseストリームを作成します。その準備として、まずはFirehoseストリームが利用するサービスロールを作成します。
信頼ポリシーはFirehoseストリーム用に以下のものを用います。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"sts:AssumeRole"
],
"Principal": {
"Service": [
"firehose.amazonaws.com"
]
}
}
]
}
ドキュメントを参考に許可ポリシーは以下のものを用います。アカウント番号などリソースに応じて書き換える必要があります。ドキュメントでは、GlueのResourceがそのままではFirehoseストリームの作成ができなかったので、*に変更しました。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Action": [
"glue:GetTable",
"glue:GetDatabase",
"glue:UpdateTable"
],
"Resource": [
"*"
]
},
{
"Effect": "Allow",
"Action": [
"s3:AbortMultipartUpload",
"s3:GetBucketLocation",
"s3:GetObject",
"s3:ListBucket",
"s3:ListBucketMultipartUploads",
"s3:PutObject"
],
"Resource": [
"arn:aws:s3:::{Firehoseストリームでエラーになったとき用のS3バケット名}",
"arn:aws:s3:::{Firehoseストリームでエラーになったとき用のS3バケット名}/*"
]
},
{
"Effect": "Allow",
"Action": [
"lakeformation:GetDataAccess"
],
"Resource": "*"
},
{
"Effect": "Allow",
"Action": [
"logs:PutLogEvents"
],
"Resource": [
"arn:aws:logs:us-east-1:{アカウント番号}:log-group:*"
]
}
]
}
次にリソースリンクを作成します。AWS CLIで次のコマンドを実行します。
※ --catalog-id でリソースリンクを作る先のカタログを指定できます。指定しない場合は、デフォルトのアカウント番号が名前になっているカタログが使われます。
※ リソースリンク名として-を使った場合、リソースリンク作成時はエラーになりませんが、Firehoseストリームでリソースリンク名を指定する際にエラーになったため、-を使うのは避けたほうがよさそうです。
aws glue create-database --database-input '{
"Name": "resource_link_to_example",
"TargetDatabase": {
"CatalogId": "{アカウント番号}:s3tablescatalog/analysis-test",
"DatabaseName": "example"
}
}'
次にLake FormationのマネジメントコンソールからS3 Tablesのテーブルに対する権限をFirehoseストリームのサービスロールに付与します。元となるテーブルとそのリソースリンクの両方に権限の付与が必要です。
まずは、リソースリンクに対する権限をサービスロールに付与します。Lake Formationのデータベース一覧で作成したリソースリンクを選択し、ActionsからPermissionsのGrantを選択します。
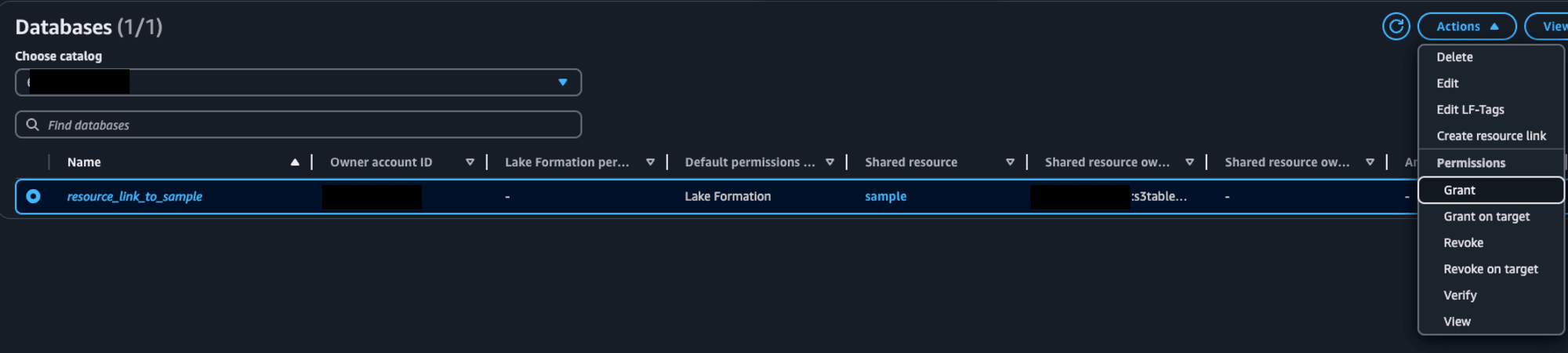
先ほど作成したFirehoseストリームのサービスロールをPrincipalsとして選択します。LF-Tags or catalog resourcesは特になにも変更しません。
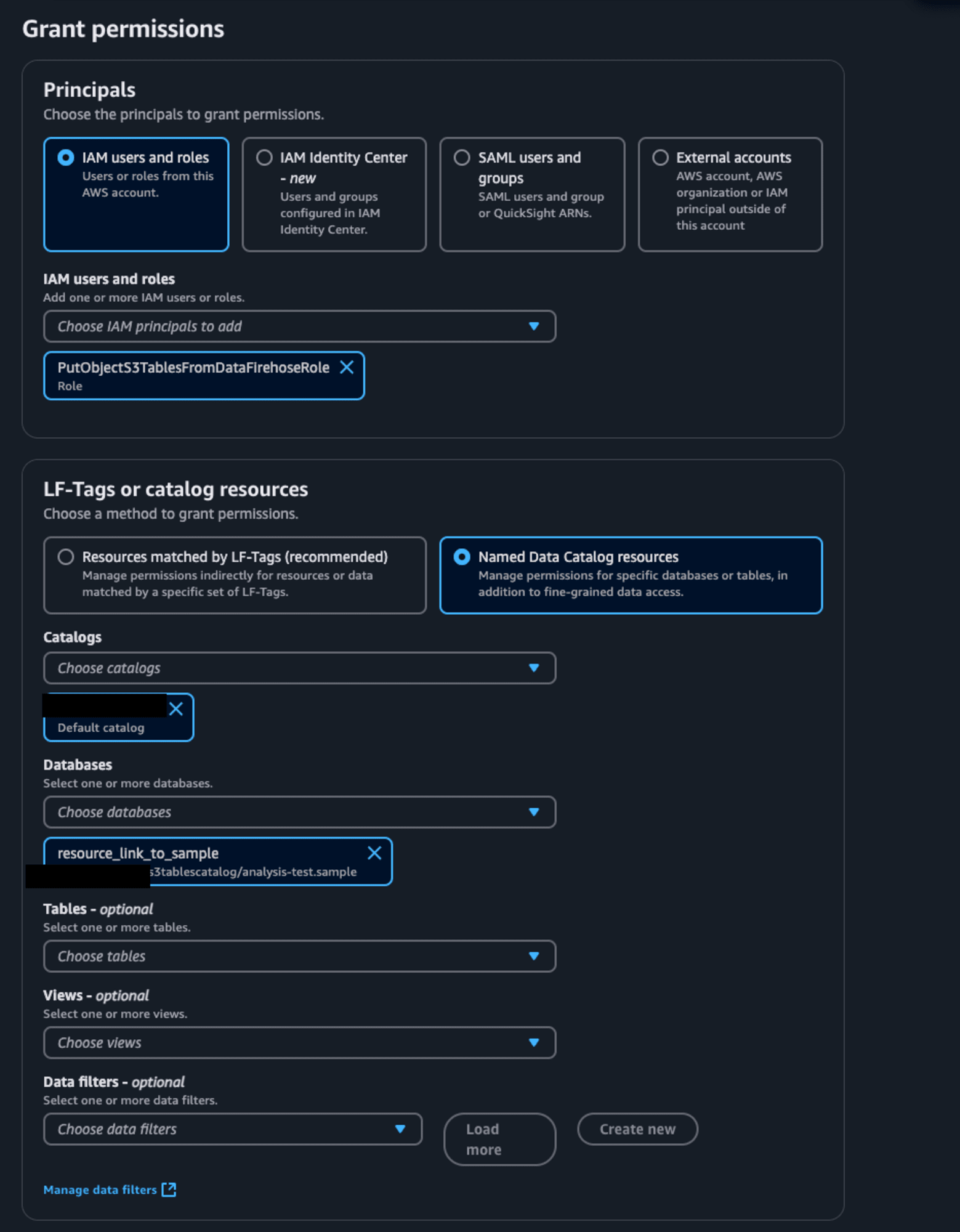
Resource link permissionsではDescribeを選択し、最後に右下のGrantを押します。
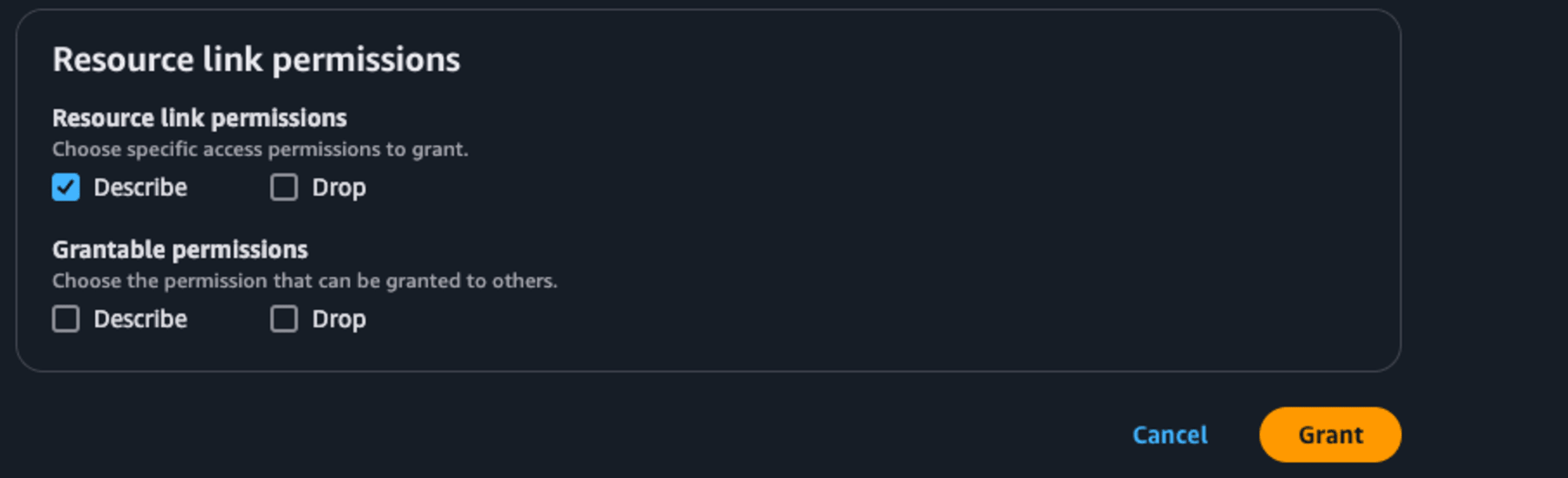
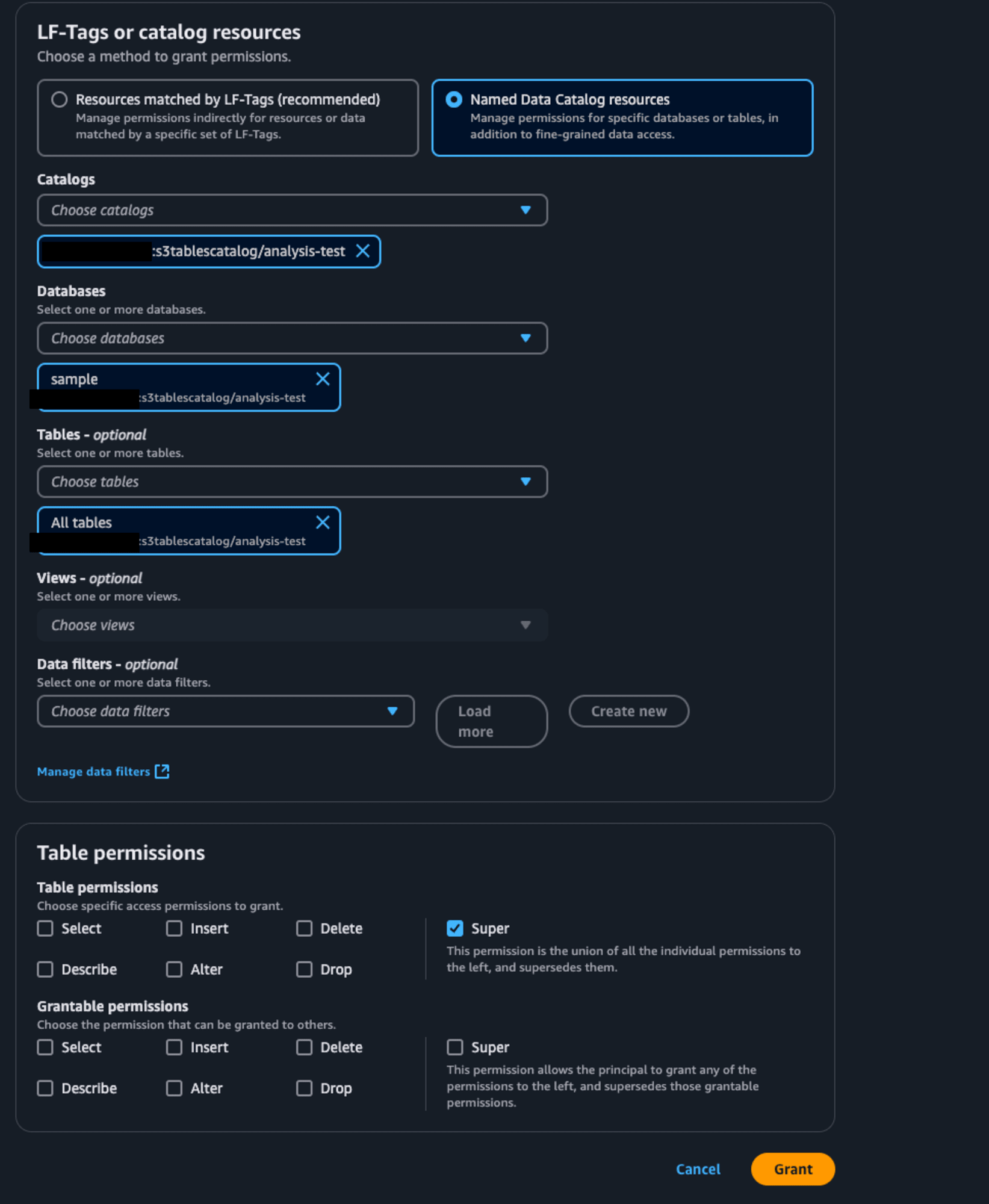
次にリソースリンクのリンク先のテーブルに対する権限をサービスロールに付与します。
先ほどと同様、Lake Formationのデータベース一覧で作成したリソースリンクを選択します。今回はリソースリンクのリンク先なので、ActionsのPermissionsの中のGrant on target(先程はGrant)を選択します。先程と同様、PrincipalsはFirehoseストリームのサービスロールを選択します。LF-Tags or catalog resourcesのTablesで対象のテーブルもしくはAll tablesを選択します。Table permissionsではSuperを選択します。
これで準備ができたので、Firehoseストリームを作成します。
Firehoseストリームを作成する
マネジメントコンソールでFirehose ストリーム のページに行き、Firehoseストリームを作成します。
ソースはDirect PUT、送信先はApache Iceberg テーブルを選択します。
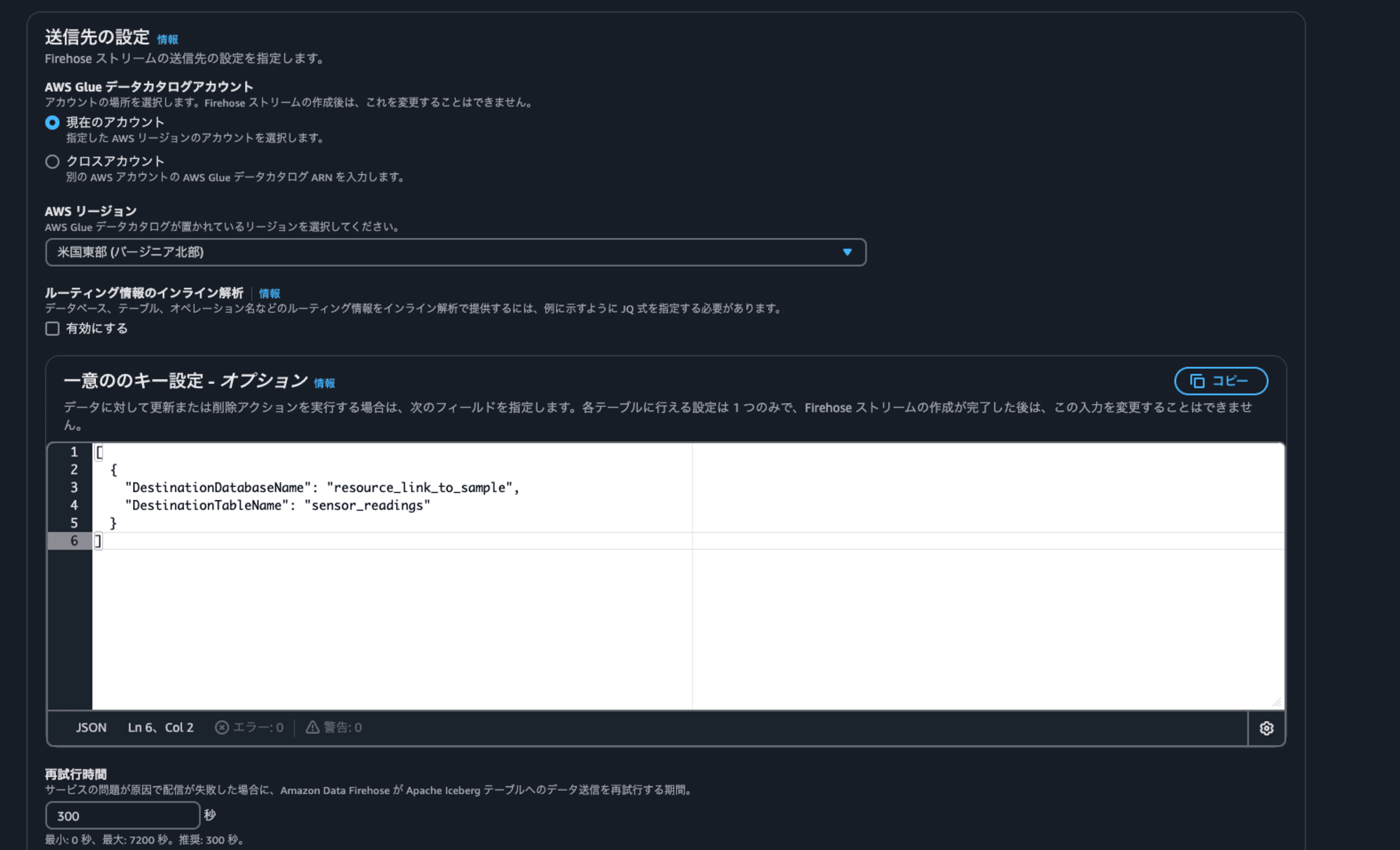
ドキュメントを参考に、送信先の設定にある"一意のキー設定"にテーブル情報を指定します。一意のキー設定とありますが、どこのテーブルにデータを配信するかの情報をここで設定します。ユニークになる列の組み合わせが無い場合もDestinationDatabaseNameとDestinationTableNameの指定が必要です。
- [必須]DestinationDatabaseName: リソースリンク名を記載します
- [必須]DestinationTableName: テーブル名を記載します
- UniqueKeys: 更新または削除アクションを実行する場合には、テーブルにおいてユニークになる列の組み合わせを記載します。
- S3ErrorOutputPrefix: 配信に失敗したときのためのS3プレフィックスを記載します
今回は指定してないですが、ルーティング情報のインライン解析を有効にして、JQ式を記載することで、レコードに応じて複数のテーブルの中からテーブルへの配信先を分けたり、レコードに応じてINSERTかUPDATEかDELETEの操作を変えることも可能です。詳細はドキュメントを参照してください。
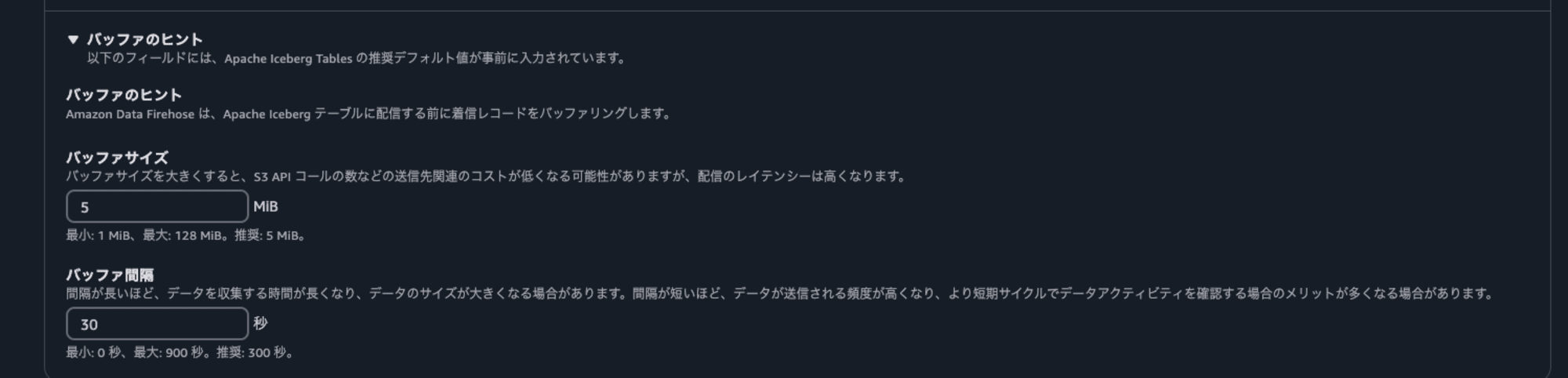
データの書き込みを早めて確認しやすくするためにバッファのヒントでバッファ間隔を短く指定しておきます。
最後にサービスロールを指定し、ストリームを作成します。
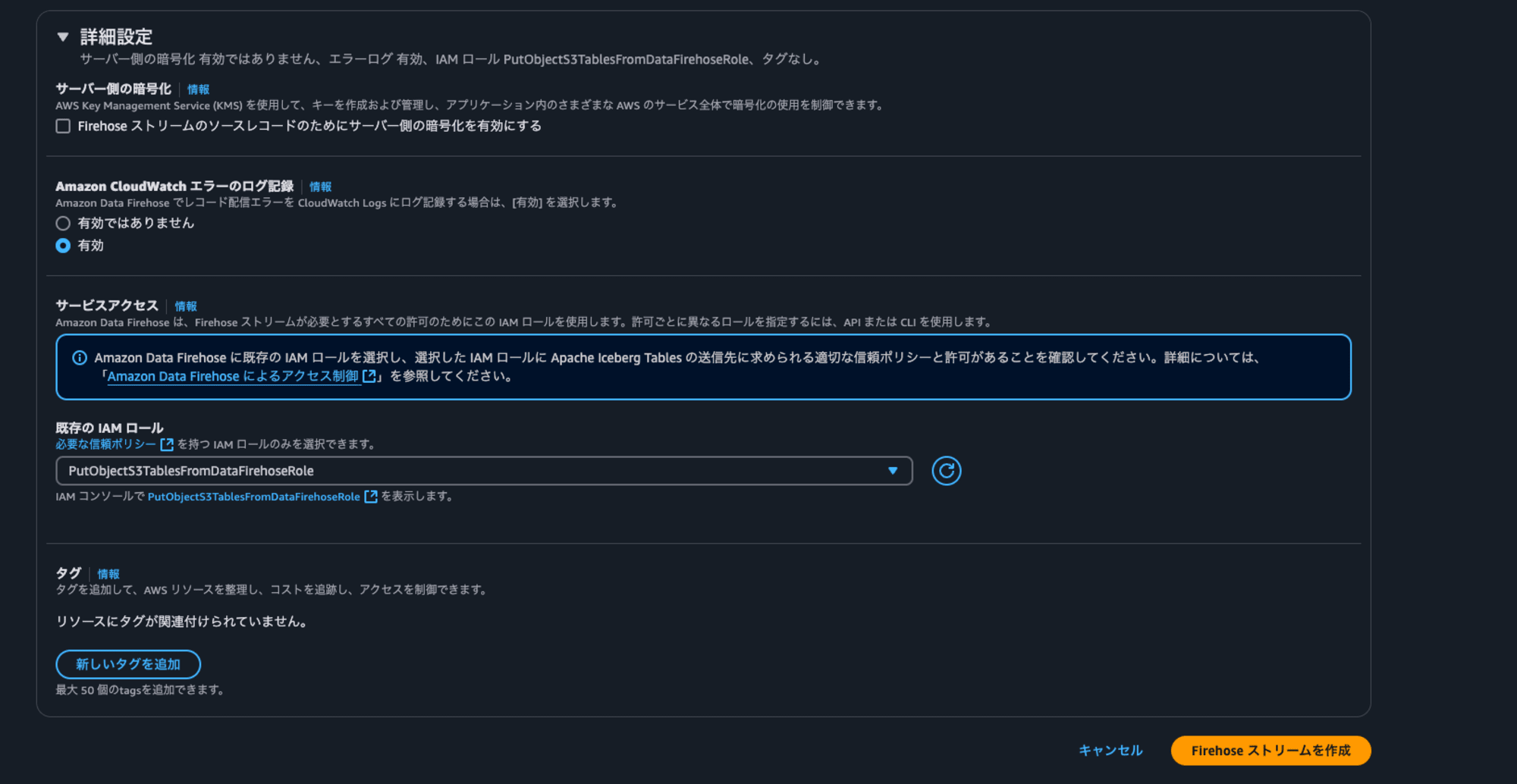
センサーデータをFirehoseストリームに送信
ストリームを作成できたら、以下のスクリプトで10件ずつのセンサーデータを10秒間隔でFirehoseストリームに送信します。JSONの加工のため、jqを使用しています。
#!/bin/bash
# 配信ストリーム名を指定
DELIVERY_STREAM_NAME="sample-s3-table-stream"
# リージョンを指定
AWS_REGION="us-east-1"
# ランダムなセンサーデータを生成する関数
generate_sensor_data() {
local sensor_id=$1 # センサーIDを引数として受け取る
# ランダムな温度 (20.00〜30.00)
local temperature=$(echo "scale=2; 20 + (30 - 20) * $RANDOM / 32767" | bc)
# ランダムな湿度 (30.00〜70.00)
local humidity=$(echo "scale=2; 30 + (70 - 30) * $RANDOM / 32767" | bc)
local timestamp=$(date -u +"%Y-%m-%dT%H:%M:%SZ") # UTCタイムスタンプ
# JSON形式でデータを生成
jq -n --arg sensor_id "$sensor_id" \
--arg temperature "$temperature" \
--arg humidity "$humidity" \
--arg timestamp "$timestamp" \
'{sensor_id: $sensor_id, temperature: ($temperature | tonumber), humidity: ($humidity | tonumber), timestamp: $timestamp}'
}
# Base64エンコードを行う関数
base64_encode() {
echo -n "$1" | base64
}
# データをFirehoseにバッチ送信する関数
send_batch_to_firehose() {
local batch_data=$1
local result
# Firehoseにデータをバッチ送信し、結果をキャプチャ
result=$(aws firehose put-record-batch \
--region "$AWS_REGION" \
--delivery-stream-name "$DELIVERY_STREAM_NAME" \
--records "$batch_data" 2>&1)
# 結果を確認
if [ $? -eq 0 ]; then
echo "Successfully sent batch: $batch_data"
echo "AWS Response: $result"
else
echo "Failed to send batch: $batch_data"
echo "Error: $result"
exit 1
fi
}
# 10秒ごとにセンサーごとのデータを10件まとめて送信
echo "Starting to send sensor data to Firehose..."
while true; do
for sensor_id in {1..10}; do
# センサーごとのデータを10件まとめる
records=$(jq -n '[]') # 空のJSON配列を初期化
for i in {1..10}; do
sensor_data=$(generate_sensor_data "$sensor_id")
encoded_data=$(base64_encode "$sensor_data")
# Firehose用のレコード形式に変換
record=$(jq -n --arg data "$encoded_data" '{Data: $data}')
records=$(echo "$records" | jq ". += [$record]")
done
# Firehose用のバッチデータをJSON文字列に変換
batch_data=$(echo "$records" | jq -c '.')
# Firehoseにバッチ送信
send_batch_to_firehose "$batch_data"
done
sleep 10
done
スクリプトの実行権限を付与し、実行します。
chmod 744 stream-sensor-data.sh
./stream-sensor-data.sh &> output.log
ある程度データを流したら、ctrl+cで終了します。
Sparkシェルからデータを確認
Sparkシェルでselectクエリを叩いてデータを確認してみます。
spark.sql("select * from s3tablesbucket.sample.sensor_readings limit 5").show()
データが入ってることが確認できます。
+---------+-----------+--------+-------------------+
|sensor_id|temperature|humidity| timestamp|
+---------+-----------+--------+-------------------+
| 1| 28.77| 46.78|2024-12-06 21:00:56|
| 2| 22.2| 60.46|2024-12-06 21:00:59|
| 3| 26.73| 59.14|2024-12-06 21:01:01|
| 4| 25.55| 33.87|2024-12-06 21:01:04|
| 5| 22.44| 61.46|2024-12-06 21:01:06|
+---------+-----------+--------+-------------------+
Athenaでクエリ実行
Lake Formationで自分自身が使っているIAMにテーブルに対する権限を付与します。Firehoseストリームのサービスロールに付与したときと同様、リソースリンクを選択して、Actionsからgrant on targetを選び、自身のIAMに対して全テーブルの権限を付与しておきます。
権限の付与が完了したら、AthenaのクエリエディタでSparkシェル同様にデータを確認してみます。
select * from s3tablesbucket.sample.sensor_readings limit 5
データが確認できました!
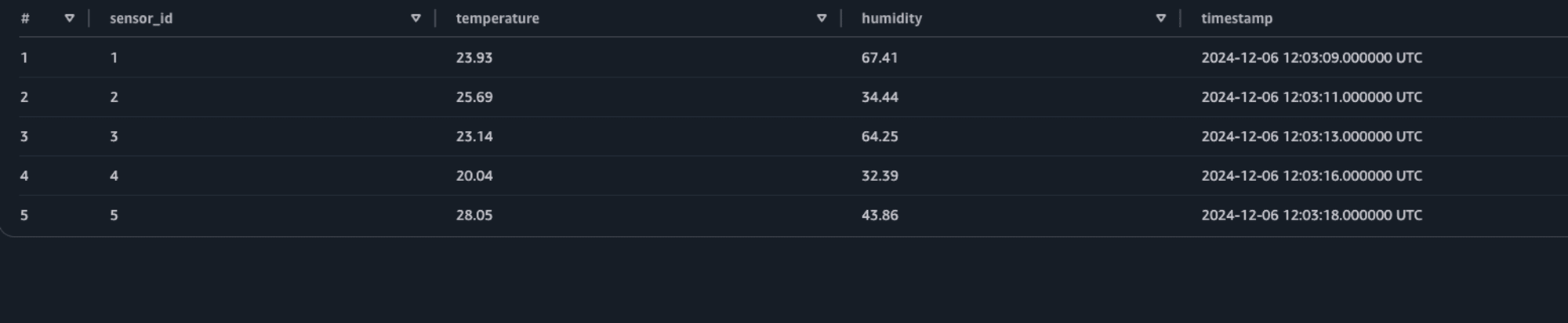
Athenaでクエリの実行ができたので、アドホックな分析や各種BIツールなどから参照といった活用も考えられます。
まとめ
Data Firehose、S3 Tables、Athenaを使ったデータ基盤を試してみた様子を紹介しました。S3 Tablesは、AWS分析サービスとの連携においてLake Formationが重要な役割を果たし、アクセス権限管理やセキュリティの強化を実現します。一方で、Sparkを使って直接S3 Tablesのテーブルを操作することで、Lake Formationを介さない柔軟な運用も可能です。また、Data Firehoseなどからのストリーミングデータの配信では、小さいファイルが多くできやすいため、S3 Tablesの自動的なコンパクション機能との相性が良さそうです。Lake FormationとGlueのデータカタログを介して、Athenaからの分析も簡単に行えました。これらの特徴から、S3 Tablesを中心とした構成は、今後のデータ基盤の有力な選択肢となりえそうです!
参考
- Amazon S3 Pricing - Cloud Object Storage - AWS
- New Amazon S3 Tables: Storage optimized for analytics workloads | AWS News Blog
- Working with Amazon S3 Tables and table buckets - Amazon Simple Storage Service
- Getting Started - Apache Iceberg™
- Apache Iceberg テーブルをクエリする - Amazon Athena
- Deliver data to Apache Iceberg Tables with Amazon Data Firehose - Amazon Data Firehose
- [アップデート]Apache Iceberg形式のテーブルデータに最適化されたストレージAmazon S3 Tablesが発表されました










